
- Introduction
- Background
- What is server side rendering?
- Perceived Performance
- SEO Considerations
- Event Loop Basics
- Problems
- Mechanics of SSR
- Render To String
- Render To Node Stream
- Rendering in Workers
- Performance Comparison
- Approaches to SSR
- Rendering at the Edge
- Rendering as a Service
- Rendering In Lambdas
- What does it all mean?
- Andrew Hagedorn
- Articles
- React SSR at Scale
React Server Side Rendering at Scale
When your your server code and front end code are written in different languages the lure of an isomorphic application can be strong. You might start hearing voices saying this like: Only write your rendering code once! and Share 95% of the application between the backend and the frontend! And on the face of it it might even sound like a good idea. But is it?
Many years ago I was working on an application with a C# backend and a Backbone.js front end and tried several approaches to simplify writing complex pages. Perhaps the most successful was sharing mustache templates templates between the backend and the frontend, but even this had massive drawbacks. So when the time came to reevaluate our stack almost half a decade ago the team ultimately decided to start using React and NodeJS on the edge to render it. This article is about what happens when you try to do that for complex web pages at scale.
Background
What is server side rendering?
To put it simply server side rendering (SSR) is taking a React client side application and generating its html on the server so that it can be included in the intial payload sent back to the browser. If you view source on website using SSR you will see something like this:
 The source of this page
The source of this page
This is not a new idea; sending down HTML in your initial payload is in fact how websites have pretty much always worked. Client side rendering (CSR) is the opposite tactic that is often used with React. Rather then rendering anything on the server the cost of rendering is pushed to the client and done exclusively in the browser in javascript. In the extreme this could be as sending a single script tag to the user:
 CSR page with just a script tag
CSR page with just a script tag
From the perspective of the developer there are some advantages to this. A browser only application is certainly a simpler mental model and you don't have to worry about maintaining a server. However, from the perspective of the consumers of your website, namely people and bots, CSR has two issues. It is not as performant as SSR and it may not allow your site to be effectively indexed by search engines.
Perceived Performance
The argument for why CSR is less performant is fairly straightforward and should be clear from the differences between the network calls of each application. For simplicity, lets assume you have a simple application with a database and the data is exposed externally on a set of REST APIs. If you were to perform SSR you would need to fetch the data from the database on the initial network call so that you can generate the html. Once in the browser, javascript resources will be fetched to make the page interactive, but the page should be visually complete once the HTML has been processed by the browser:
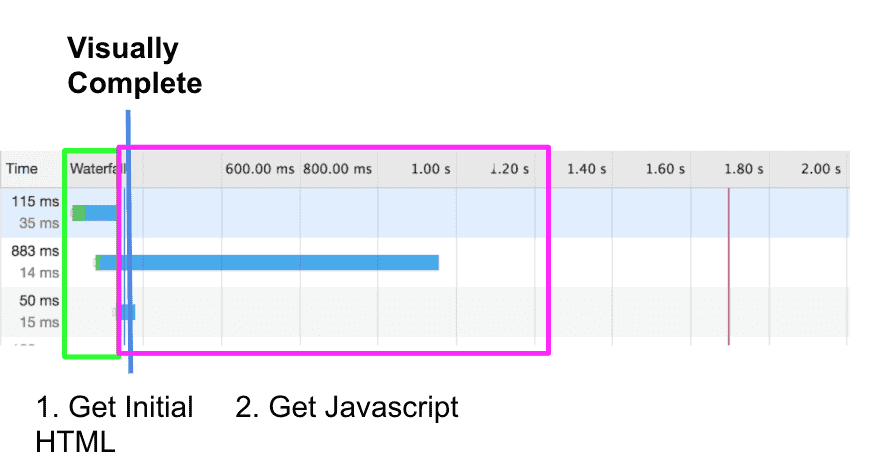
In the case of CSR, the javascript must be fetched by the browser and run prior to even starting to fetch the data and render the page:

You can optimize your APIs as much as you want but you will be hard pressed to make the additional latency of fetching your javascript and data over the public internet faster than a network call within your data center.
Fetching the data over the network is not the only option, but no other option completely removes the additional costs. For instance, you could bootstrap the data and only pay the cost of fetching javascript and rendering the HTML in the browser. This can improve the performance of your website substantially, but due to the amount of javascript generally required to render React pages and the costs of rendering CSR still has a much worse perceived performance by the user. Instead of immediately seeing the content in the HTML of the page while the javascript downloads they will either see a spinner or no content until React has fully rendered. On mobile devices this is particularly noticable.
SEO Considerations
From the outside, SEO appears to be mostly black magic and luck. I am not sure that as you know more that becomes less true. In 2015 when we were evaluating how we should iterate on our front end stack a key question was whether CSR and SEO were compatible. There were rumors at the time that Google would index your pages, but rumor is not a reliable way to build a business. Luckly we had a portion of our website that had real traffic, ranked for SEO, was simple to replicate, and had absolutely no business value. We decided spend to a week or two and rewrite those pages as a client side application and observe what happened.
Our Google traffic showed a meaningful dip on these pages and our Bing traffic went to zero essentially overnight (also, it's quaint that there was a time we cared about Bing). When we reverted to the original pages the traffic evenually recovered. This made it clear that CSR was not going to work for us and we began to experiment with SSR.
Fast forward 5 years, and it is still not completely clear how effectively client side websites are indexed. At the very least CSR websites are indexed more slowly than their SSR counterparts. There is also a somewhat logical case for this to be true. Assuming that it is less resource intensive to download just HTML vs. headless rendering of a webpage it should be much more cost effective for crawlers to download more HTML and render fewer webpages fully. An even bigger concern is that Google increasingly factors performance into ranking. This means that some of the characteristics of a CSSR application such as a long Time to Interactive (TTI) or a large Cumulative Layout Shift (CLS) could deeply hurt your website's rankings.
The worst case is grim. There are some reports of CSR pages that are indexed partially or not at all. When search engines are a channel of new users for your business going with CSR is not a risk you should take.
Event Loop Basics
The core underpinning of NodeJS's ability to have non-blocking I/O within a single threaded application is to push as much as possible to the system kernal which is likely to be multithreaded. When operations are completed it can then put callbacks onto a system of queues known as the event loop. The limitations of this structure are key to understanding why SSR does not perform well at scale.
To understand why this is problematic, lets first take a quick look at an incredibly oversimplifed model for the event loop. In this model there will be two stages that are constantly repeated:
- Process incoming requests
- Process I/O callbacks
So lets consider an application that receives 1 request every second and each request makes a single API request that takes 2 seconds and then does 3 seconds of processing. The columns of the following table represent the number of requests in a handful of states: incoming and waiting to be processed, waiting for data callbacks, waiting to process data, and processing. Lets see what happens as time passes:
| Time | Incoming | Waiting on Data | Processing |
|---|---|---|---|
| 1 | ○ | ||
| 2 | ○ ○ | ||
| 3 | ○ | ○ | ○ |
| 4 | ○ ○ | ○ | ○ |
| 5 | ○ ○ ○ | ○ | ○ |
| 6 | ○ ○ ○ ○ | ○ | |
| 7 | ○ | ○ ○ ○ ○ | ○ |
| 8 | ○ ○ | ○ ○ ○ ○ | ○ |
| 9 | ○ ○ ○ | ○ ○ ○ ○ | ○ |
| 10 | ○ ○ ○ ○ | ○ ○ ○ ○ |
Initially, requests are able to be processed immediately and start fetching data. However, once any processing happens requests quickly stack up and subsequently enter the processing stage at the same time. While that set of requests is being processed (and blocking the event loop) even more requests stack up. Eventually the processing stage takes so long that your healthchecks cannot be processed in time and the server is killed.
In slightly more real life sitution, lets consider a small express server endpoint:
app.get('/processing', (req, res) => {
const delay = parseInt(req.query.delay || '1000', 10);
const now = new Date().getTime();
while(new Date().getTime() < now + delay) {
; // spin and block the event loop
; // you should never do this in real life...
; // but this simulates blocking CPU like SSR
}
res.send('OK');
});If we apply load with increasing CPU delays we see the event loop delay and response times significantly degrade:
It is hopefully a little more clear that NodeJS works well enough when its doing async IO and very little processing on the results. Any significant CPU on the event loop will block all other actions and cause your server to perform incredibly poorly.
What is SSR? Pure CPU.
Is SSR a good fit for a NodeJS server? Not out of the box.
Problems
Lets assume you have a NodeJS server performing server side rendering. For very simple pages at medium levels of load or complex pages under low levels of load everything will probably work out. However at high load and with complex pages with many React components you will see issues:
- 500 errors
- Increased Latency
- Unhealthy hosts
The reason for this is pretty straight forward. SSR is all CPU which means that trying to perform many renders at once will clog up your event loop and prevent incoming requests from being processed. At enough load, this means you cannot service incoming user requests, but more importantly you can't service your healthcheck either. For simple applications you might never reach this point. Unfortunately, for non-trivial applications "enough load" becomes remarkablely small.
Assuming your web application is stateless you can easily scale this horizontally and spend money to solve the problem. However, you are still vulnerable if your application gets a burst of traffic given a non-zero time to detect the increased load and spin up new instances of the application.
Mechanics of SSR
So far we have talked a lot about why SSR is important and also why SSR might not be a great workload for NodeJs, but we have talked very little about how SSR is performed in a React application. For the purposes of this discussion lets consider the most barebones version of an application:
- Receive a request
- Get the data for the page
- Render a React component
- Return the html
Using express, this could be as simple as this:
app.get('/render-page', async (req, res) => {
// A database or service call
const data = await getData();
const html = renderTheComponent(
<Component data={data} />
);
res.send(html);
});The devil is of course in the details of renderTheComponent and React has provided a couple of options. The rest of this section will describe those options and to evaulate the performance of each we will consider a similar set up to the previous event loop test; the difference will be that instead of busy waiting we will be rendering a React component. While slightly flawed, it should at least give us an idea how these might perform in a more production like environment with complex React pages.
Render To String
In the beginning there was really only one option for implementing renderComponent; you would use a method in react-dom called renderToString. The implementation would simply be:
const ReactDom = require('react-dom/server');
app.get('/render-page', async (req, res) => {
const data = await getData();
const html = ReactDom.renderToString(
<Component data={data} />
);
res.send(html);
});In the browser this is paired with ReactDom.hydrate() to load the rendered HTML, rebuild the virtual DOM, and attach event handlers (client side performance is another can of worms...). Overall this method works, but renderToString is a fully blocking operation and for large pages can be time consuming. Alternatively, if you do not intend to hydrate the application on the browser you could use ReactDom.renderToStaticMarkup; from a performance perspective you might save a couple bytes over the wire, but otherwise it is the same as renderToString.
Render To Node Stream
React 16 introduced a new option for server side rendering: ReactDom.renderToNodeStream. It renders the same HTML as renderToString, but does so in smaller chunks. This means there are two key differences for the performance of your application:
- It allows you to stream the HTML back to the user as it is generated
- It can partially unblock the event loop if you release it as each chunk is generated
Lets first consider a basic implementation:
app.get('/render-to-stream', (req, res) => {
const data = await getData();
const stream = ReactDom.renderToNodeStream(<Component data={data} />);
stream.on('error', e => { /* handle the error */ });
stream.pipe(res);
});renderToNodeStream however, does not solve the fundamental problem that rendering is sharing the event loop with handling incoming requests and callbacks from fetching data. In practice, for large components the render cycle will still block the event loop for a substantial amount of time as it initially sets up the component tree to be rendered and for each chunk that it renders.
Rendering in Workers
In Node 12, a new option for rendering became available when worker threads became a stable feature. With worker threads you can push the CPU intensive rendering off the main event loop so that it can focus on the I/O of incoming requests and callbacks from fetching data. This is a more complicated solution and requires that you queue requests if there are no free workers to perform rendering:

In code there are now two parts. The main application:
// app.js
const { StaticPool } = require('node-worker-threads-pool');
const pool = new StaticPool({
size: 10,
task: '/dist/worker.js',
});
app.get('/render-in-worker', (req, res) => {
pool.exec({
data
}).then(result => res.send(result));
});And the implementation of the worker:
const { parentPort } = require('worker_threads');
parentPort.on('message', function({ data }) {
const html = Dom.renderToString(<Component data={data} />);
parentPort.postMessage(html);
});Using workers can definitely improve the overall health of your node rendering server under load, but its important to note that this is not a silver bullet:
- The event loop will be held as you push data to the worker and html back when its done
- You might need to provision more CPU to account for additional CPU intensive worker threads.
Performance Comparison
There are multiple options for server side rendering, but how do they stack up on performance. To attempt to answer lets create a toy component and render it under increasing load.
As we would expect rendering in the main process causes significant delays in the event loop, but there are two interesting observations. First, in this example rendering to a stream versus directly to a string shows no benefit for the event loop. Second, when workers are used there is virtually no impact on the event loop of the main process at at all.
Response times show a similar story; the response times when rendering in the main process degrade more quickly than when rendering in workers.
Approaches to SSR
At this point you might be asking the question: Should you even bother? That depends on the context of your application. For simple applications the best route is to just to generate static HTML offline and dump it on a CDN. There is no need to spend time and money repeatedly rendering the exact same content for all users. This is also true for many complex applications too.
However, for the purposes of this article this case is not very interesting. So lets assume your requirements are such that you need to dynamically generate the content on the page. And lets also assume that you are married to performing SSR with React and we can eliminate the case of generating your HTML in another framework and language.
Rendering at the Edge
The first option is to just have a NodeJS server at the edge that handles inbound requests, fetches data, and renders out HTML:
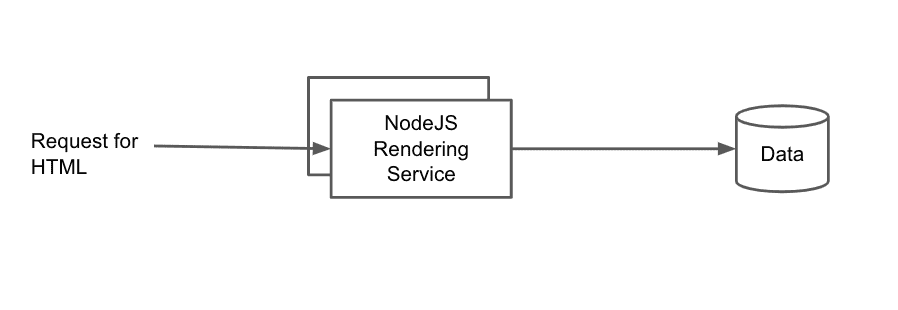
This is the exact scenario that was used to describe the event loop issues that SSR has, so the downsides of this setup should already be clear. If you go with this architecture your best performance option is to perform your rendering in workers so that the main event loop is free to handling inbound requests.
Rendering as a Service
Another option is to have a service at the edge which is responsible for handling incoming requests and gathering data, but delegates rendering to another pool of services:
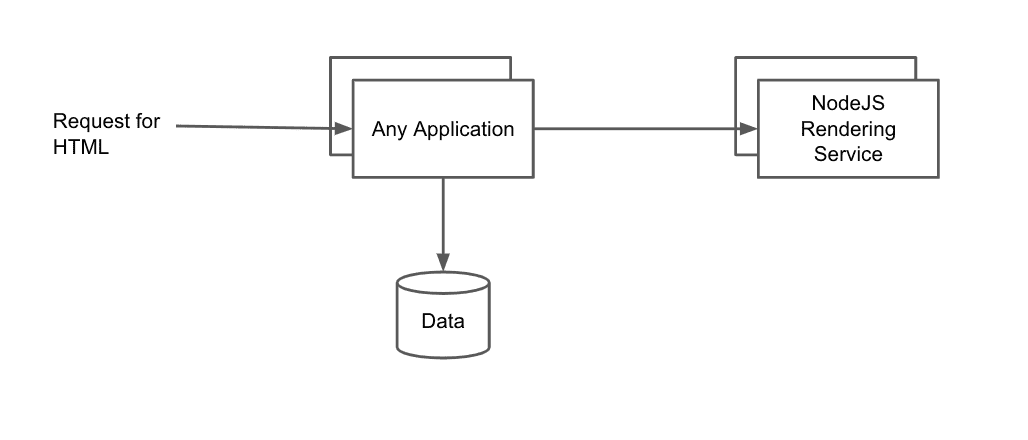
This is the approach of Hypernova, a project from Airbnb. I have not used it professionally, but this approach has a couple clear drawbacks when compared to rendering at the edge:
- You have a large and vague contract over a service boundry that is easy to violate
- You might need to deploy seperate services in lockstep to prevent outages
- It has all the same event loop issues as an edge renderer
From my perspective this makes the use case for rendering as a service is very limited. It only really makes sense if you are trying to render partial chunks of HTML from a codebase written in something other than NodeJs. Otherwise, if you are rendering full pages in React and you are already comfortable having another service in your ecosystem it's just less complicated to go with rendering at the edge.
Rendering In Lambdas
The previous two approaches are server based which means that there is a shared event loop that you must work around. An alternative approach is to go serverless so that each request has its own event loop:

This is the approach used by Vercel, the makers of NextJs. This approach has the clear upside of avoiding a shared event loop between requests since each request is its own isolated lambda invocation. At low scale this can be a very cost efficient option especially if you can skirt under your cloud providers free tier invocation counts though your performance may suffer due to cold starts.
At scale the dollar cost becomes less friendly; a lambda running constantly in parallel is potentially just a much more expensive server. On AWS you are also likely to start running into platform limits for concurrency, especially if you have other workloads doing significant processing in lambdas. You also run into all the pros and cons of lambdas in general, so whether this is a good idea or not will also depend on the skills of your organization.
What does it all mean?
My experience is with wrestling NodeJS servers doing SSR at the edge and I have moved through all of the stages of grief with that solution. Delegating rendering to workers has alleviated the server health issues I had observed while rendering on the main event loop of the application. When my team started down this road I don't think we realized how much complexity and work would be required to maintain acceptable performance with React SSR. Ultimately, you are trying to make NodeJS do something it is explicitly not good at which begs the question why are you doing it at all?
Other Posts
Technology
- React SSR at Scale
- TravisCI, TeamCity, and Kotlin
- The Good and the Bad of Cypress
- Scaling Browser Interaction Tests
- Exploring Github Actions
- Scope and Impact
- Microservices: Back to the Future