
- Andrew Hagedorn
- Articles
- getDataFromTree
getDataFromTree Considered Dangerous
When Technology Bites Back
This is a story of how a single line of code destroyed the performance of a website.
As with all things, context is important. It was 2018 and we had a website built in React performing server side rendering (SSR) in NodeJs. At the time there were few options for rendering React server side. You pretty much had one function renderToString:
const ReactDom = require('react-dom/server');
app.get('/render-page', async (req, res) => {
const data = await getData();
const html = ReactDom.renderToString(
<Component data={data} />
);
res.send(html);
});For the server to perform well everything on the server should be relatively light weight. Fetching data from APIs and routing incoming requests definitely fits in this category. However, SSR with React is CPU intensive since it has to walk the component tree and generate the HTML for the React component. As you might expect, this does bad things to the NodeJS event loop, but given the lack of options available in the React ecosystem you either lived with it or you didn't do SSR with React.
Enter the Apollo client into our codebase. At the time we had an opinionated developer who decided thinking about what data the page needs and fetching that in one request was complicated for developers. The Apollo client had a function named getDataFromTree which they decided was the solution to this problem. Developers could wrap their components in an Apollo provided higher order component that was responsible for the state machine of fetching data from GraphQL. And getDataFromTree would look at a page component and figure out all the queries defined in its sub-components and fetch the data.
From the developer perspective that sounds nice. Less thinking and your page still renders with its data. So we quickly added this into our codebase without thinking much more about it. Time passed and our performance suffered. It came to my attention and I immediately was suspicious of getDataFromTree and looking at the code confirmed why. It was roughly:
foreach (component in ComponentTree) {
component.componentWillMount();
component.render();
}So to gather all the data it needed to touch every component and attempt to trigger the higher order component. All told this function performed worse than rendering the final HTML and was completely avoidable. So I feature flagged a change to remove it it and temporarily flipped the flag so I could observe the change. It was a stark difference:
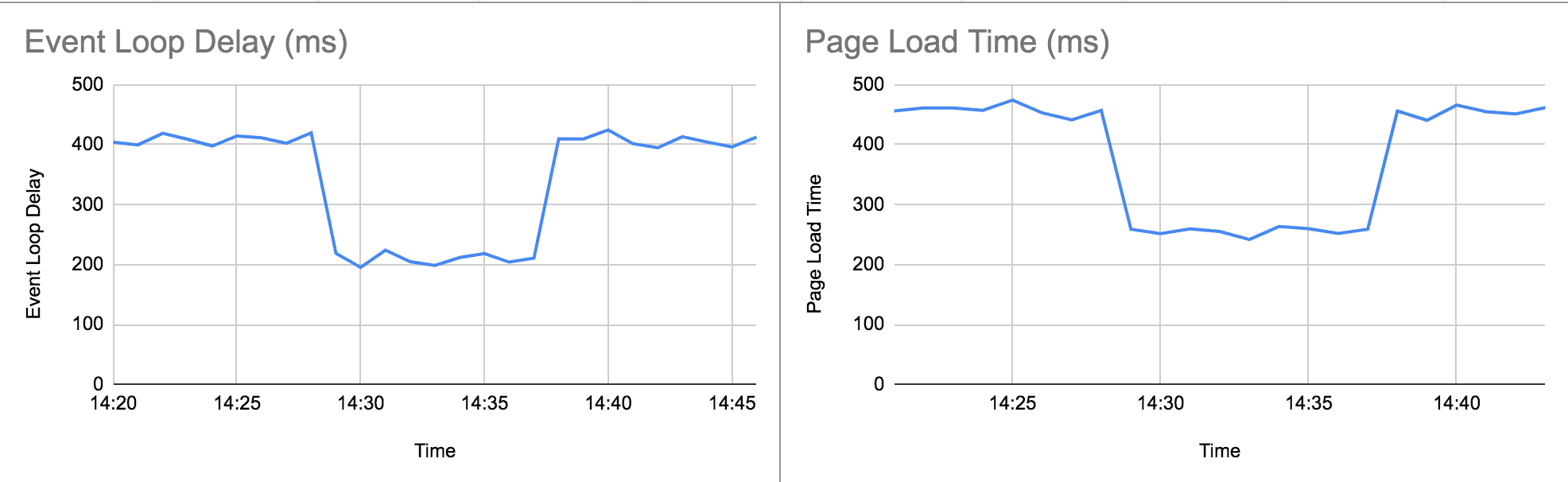 A recreation of a graph of the performance change
A recreation of a graph of the performance change
Worse, we did this on all pages including those that required zero GraphQL requests. All overhead, no gain.
Lovely.
It's been a few years and Apollo Client has probably changed a fair bit since thing. However, as a relatively recent issues on github suggests if an idea is fundamentally not going to be performant there is not much you can do. And internally, this provided a lesson to the team; open source tools and libraries are not magic. They are as good or bad as the code backing them and due diligence is an important step in adding a new library into our code base.
Other Posts
Technology
- React SSR at Scale
- TravisCI, TeamCity, and Kotlin
- The Good and the Bad of Cypress
- Scaling Browser Interaction Tests
- Exploring Github Actions
- Scope and Impact
- Microservices: Back to the Future